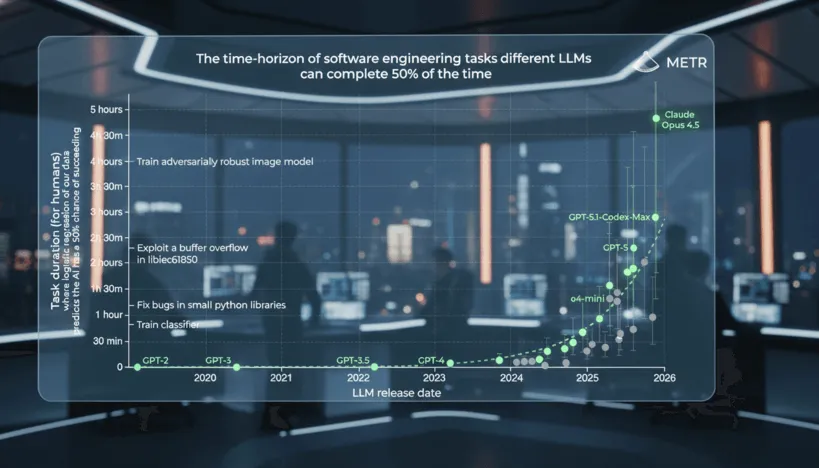
- Модель Claude Opus 4.5 от Anthropic установила рекорд автономности, успешно справляясь с задачами длительностью до 4 часов 49 минут с вероятностью 50%.
- Показатель автономности удваивается примерно каждые 7 месяцев, начиная с 2019 года, когда GPT-2 могла работать лишь несколько секунд подряд.
- При более строгом уровне надежности в 80% автономность Opus 4.5 снижается до 27 минут, что сопоставимо с предыдущими моделями.
Организация METR, специализирующаяся на оценке способностей искусственного интеллекта, недавно опубликовала результаты тестирования модели Claude Opus 4.5, разработанной Anthropic. По их данным, данная модель способна автономно выполнять задачи продолжительностью около 4 часов 49 минут с достижением 50%-ной вероятности успеха. Этот показатель стал новым рекордом среди всех протестированных на сегодняшний день систем, значительно опередив прежнего лидера — GPT-5.1-Codex-Max от OpenAI, чей горизонт автономности составлял 2 часа 53 минуты.
Отличительной особенностью методики METR является оценка не просто точности ответов на стандартных тестах, а способности ИИ работать независимо с продолжительными, разнообразными задачами. В тестах использовались задания разной направленности — от добычи информации в интернете до решения задач по кибербезопасности и обучения моделей машинного обучения. Анализ показал, что с середины 2019 года, начиная с GPT-2, автономность моделей растёт экспоненциально, примерно удваиваясь каждые семь месяцев.
Однако исследователи подчеркивают необходимость осторожного восприятия ответственности результатов. Доверительный интервал измерения автономности Opus 4.5 весьма широк — от 1 часа 49 минут до более чем 20 часов. Это связано с недостатком очень длительных заданий в текущем тестовом наборе, что ограничивает точность оценки максимальной автономности системы.
Кроме того, при повышении требования к надежности выполнения задач (уровень успеха 80%) показатель автономности Opus 4.5 существенно снижается до примерно 27 минут — уровня, схожего с конкурентами из последних поколений ИИ. Таким образом, пока что достижение продолжительных задач с высоким уровнем уверенности остаётся сложной проблемой. Это означает, что хотя Opus 4.5 способен решать задачи большой длительности, его стабильность в этом аспекте не превосходит более ранние модели.
Если тенденция удвоения автономности сохранится, по прогнозам METR, к концу текущего десятилетия искусственный интеллект сможет успешно выполнять проекты, длящихся около месяца, без вмешательства человека. В то же время критики подчёркивают ограниченность нынешней методики METR — в релевантном диапазоне продолжительности задач от 1 до 4 часов всего 14 кейсов, при этом тематика заданий смещена в пользу кибербезопасности и программирования на ML.
Организация METR намерена доработать и расширить тестовый набор, чтобы в будущем более точно измерять прогресс в автономности ИИ-моделей.







