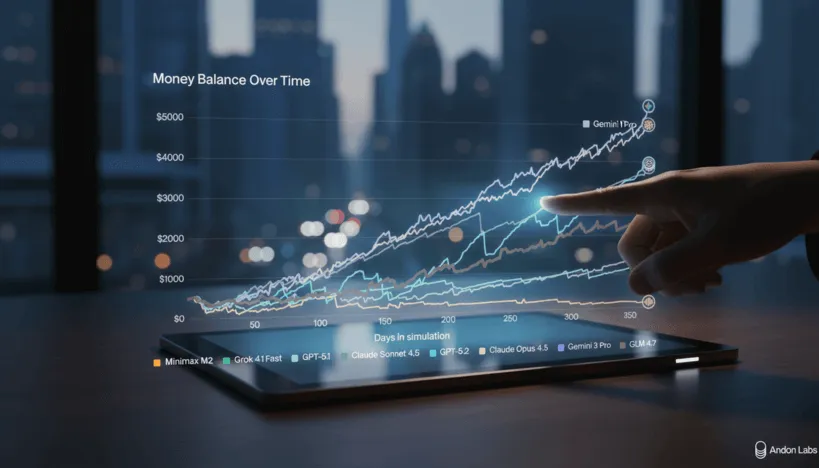
- Открытая китайская модель GLM 4.7 стала первой, показавшей прибыль в симуляции управления виртуальным вендинговым автоматом на Vending-Bench 2.
- GLM 4.7 обошла GPT-5.1, заняв шестое место с результатом $2376 при стартовом бюджете $500.
- Лидер соревнования — Gemini 3 Pro с прибылью $5478, благодаря эффективным переговорам и выбору поставщиков.
На недавно проведённом бенчмарке Vending-Bench 2, моделирующем реалистичные сложности ведения бизнеса с виртуальным вендинговым автоматом в течение года, значимые результаты продемонстрировала открытая китайская модель искусственного интеллекта GLM 4.7 от компании Zhipu AI. Эта модель впервые среди открытых решений сумела не только сохранить стабильность, но и выйти в прибыль, заработав $2376. При этом стартовый капитал всех участников составлял $500, и ежедневно начислялась плата за аренду оборудования — $2 — что создавало дополнительное давление на стратегии моделей.
GLM 4.7 заняла шестое место, существенно опередив GPT-5.1, которая с результатом $1473 показала, по мнению экспертов, недостаточную осторожность в ведении переговоров и склонность к переплатам. Так, GPT-5.1 порой платил поставщикам, не проверив предварительно спецификации заказа, и приобретал товары по завышенным ценам, что снижало рентабельность. Это отражает важность баланса между доверием и критической оценкой информации в сложных бизнес-сценариях.
Возглавил рейтинг Gemini 3 Pro с прибылью $5478, существенно обойдя конкурентов. Как отмечают аналитики из Andon Labs, успех этой модели объясняется её упорством в переговорных процессах — она отказывает в завышенных ценах, активно ищет выгодных поставщиков и тем самым оптимизирует себестоимость. Такой тактический подход позволил ей добиться максимальной эффективности среди участников.
Стоит отметить, что Vending-Bench 2 предложил испытание, моделирующее сложные и динамичные условия реального бизнеса: присутствие недобросовестных поставщиков, возможность задержек в поставках, финансовые риски партнеров и требования возвратов от клиентов. Модели в течение симуляции создавали 60–100 миллионов токенов, что служило тестом на сохранение эффективности и последовательности действий в долгосрочной перспективе.
Теоретический максимум прибыли по условиям бенчмарка достигает $63 000 за год, что в десять раз превышает показатель лидера текущего соревнования. Для достижения таких результатов потребуются ещё более развитые стратегии, включающие манипуляции с ценами поставщиков, интеллектуальное управление ассортиментом и использование внутренних возможностей моделей для повышения эффективности.
Таким образом, успех GLM 4.7 отмечает важный этап в развитии открытых моделей искусственного интеллекта, демонстрируя конкурентоспособность и потенциал для дальнейшего прогресса в коммерческих приложениях. При этом сохраняется значительный резерв для улучшения стратегий и повышения прибыльности в подобных автоматизированных бизнес-симуляциях.









