
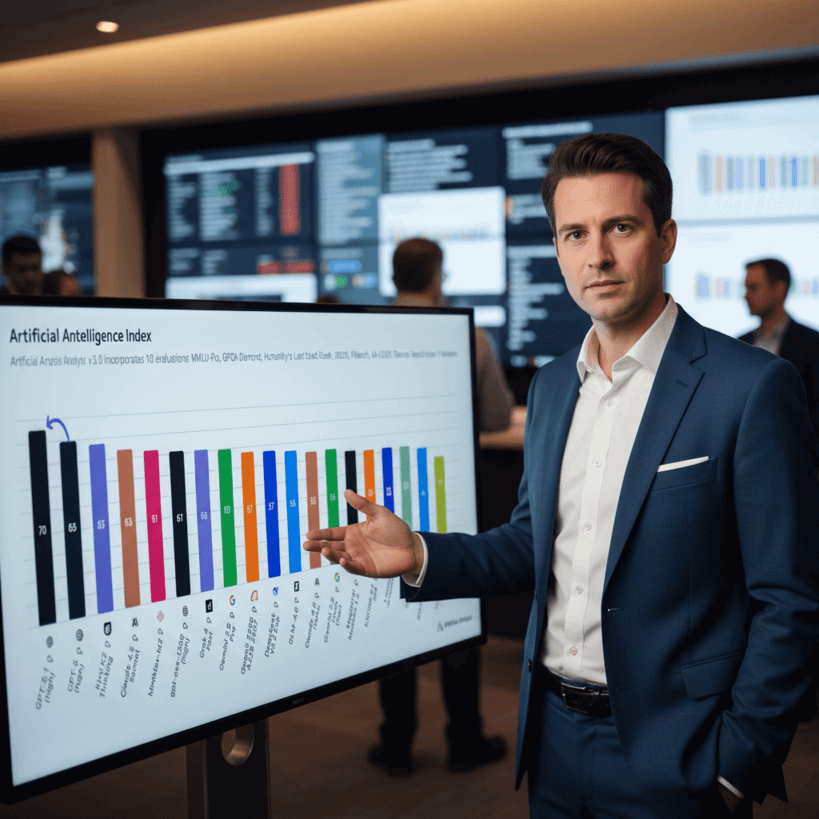
- GPT-5.1 Thinking High заняла первое место в обновлённом индексе Artificial Analysis Intelligence Index с результатом 70 баллов, опередив предыдущие версии и конкурентов.
- Модель продемонстрировала значительный прирост в бенчмарке TerminalBench, оценивающем агентские возможности, и улучшенную эффективность использования токенов при сопоставимой стоимости API.
- Версия GPT-5.1 для кодинг-агента Codex лидирует в бенчмарке SWE-Bench по решению реальных задач программной инженерии, показывая высокий уровень качества генерации патчей кода.
Недавно был опубликован обновлённый Artificial Analysis Intelligence Index — комплексный сводный индекс, предназначенный для оценки эффективности современных систем искусственного интеллекта на основе результатов различных бенчмарков. В новом рейтинге заметным лидером стала модель GPT-5.1 Thinking High, которая получила 70 баллов, обойдя своего предшественника GPT-5 Thinking High (68 баллов) и других известных конкурентов, таких как Kimi K2 Thinking, Grok 4 и Claude Sonnet 4.5.
Основной прирост GPT-5.1 объясняется значительным улучшением в бенчмарке TerminalBench, который проверяет агентские способности ИИ — показатель вырос на 12 процентных пунктов. Авторов индекса также привлекли более естественные и «человечные» ответы модели, а также её повышенная экономичность при использовании токенов. Примечательно, что стоимость API для GPT-5.1 осталась на уровне предыдущей версии, однако суммарные расходы на прогон всех бенчмарков снизились с $913 до $859, что говорит об оптимизации вычислительных затрат.
Помимо этого, все версии GPT-5.1 продемонстрировали высокие результаты в Design Arena — тесте, оценивающем взаимодействие ИИ с фронтендом и пользовательскими интерфейсами. В данном направлении ключевыми конкурентами остаются модели серии Claude 4.x.
Особое внимание заслуживает версия GPT-5.1, ориентированная на задачи программирования — кодинг-агент Codex. В бенчмарке SWE-Bench, который фокусируется на способности ИИ решать реальные задачи программной инженерии и представляет собой набор задач из GitHub с акцентом на генерацию правок кода, данная модель заняла первое место. В частности, в тесте SWE-Bench Verified — версии с 500 задачами, проверенными вручную профессиональными программистами — GPT-5.1 продемонстрировала точность 76,3%.
Стоит отметить, что полный набор SWE-Bench включает 2000 задач без ручной модерации, что затрудняет «заточку» моделей под конкретные тесты и обеспечивает более надёжную оценку универсальных возможностей искусственного интеллекта в программировании.
Таким образом, GPT-5.1 Thinking High предстала перед экспертным сообществом как самый продвинутый и эффективный интеллект на данный момент, сочетая в себе высокую производительность по разным направлениям и разумное использование ресурсов.


